Kaggle,Web Traffic Time Series Forecasting,1st place solution
Kaggle,Web Traffic Time Series Forecastingの1st place solutionのメモ.Wikipediaのpageviewを予測するコンテスト.解法のポイントは,一年前と四半期前の値を特徴量として追加し,RNN seq2seqを使うこと.
概要
TL;DR
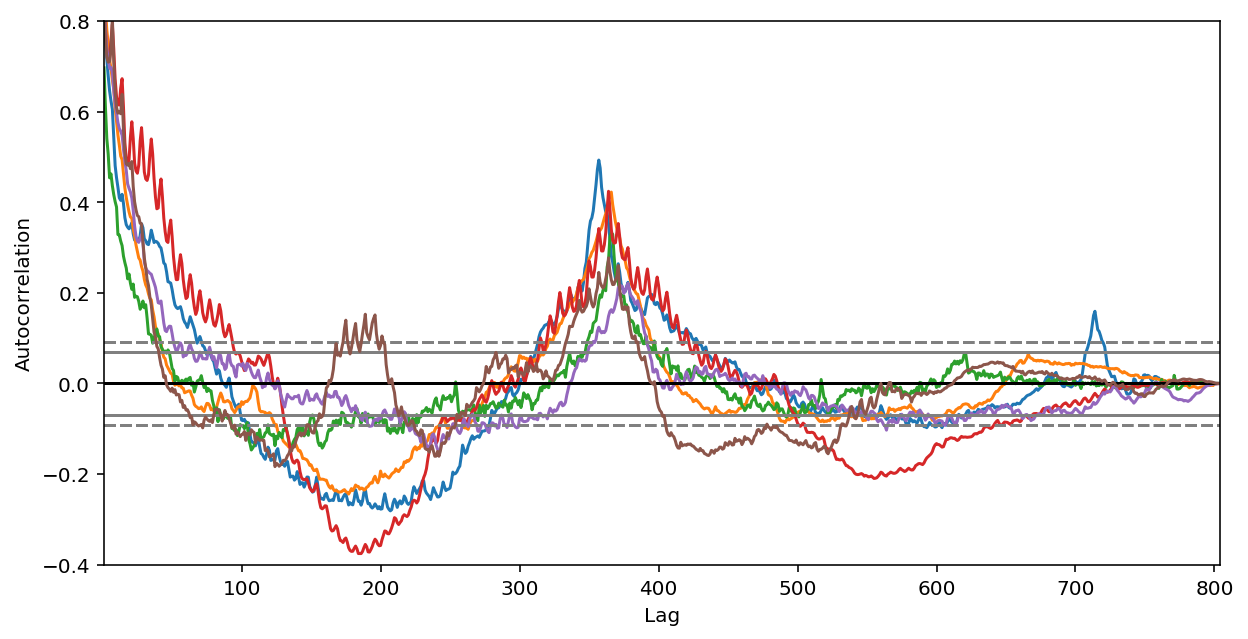
予測には2つの情報を用いた:
- ローカルな特徴量.自己相関モデル,移動平均モデル,季節性モデルなど.
- グローバルな特徴量.年周期,四半期周期のトレンド.
RNN seq2seqを利用した理由は:
- RNNはARIMAの自然な拡張と考えられるし,柔軟で表現力が高い.
- RNNはノンパラメトリック.
- RNNはどんな特徴量も簡単に扱える.
- seq2seqはこのタスクに適していると考えた.直前の時系列の予測値を入力として使うため,誤差が蓄積されやすいため,結果として極端な予測は避けるようになる1.
- Deep learningは流行っている.
Feature engineering
利用した特徴量は:
- pageviews:
log1p()で変換したビュー数. - agent,country,site:ページのURLから抽出.
- year-to-year autocorrelation,quarter-to-quarter autocorrelation:年周期や四半期周期のトレンドを捉えるため.
- page popularity:人気のページとそうでないものは,動きが異なるため.
- lagged pageviews:365日前と90日前のpageview.
Feature preprocessing
One-hot encodingしたカテゴリカル変数を含む,全ての特徴量をそれぞれ独立に正規化した.時不変な特徴量(countryなど)を時系列データ長にtf.tile()で変換した.
学習用データは,固定長でランダムに抽出した.
Model core
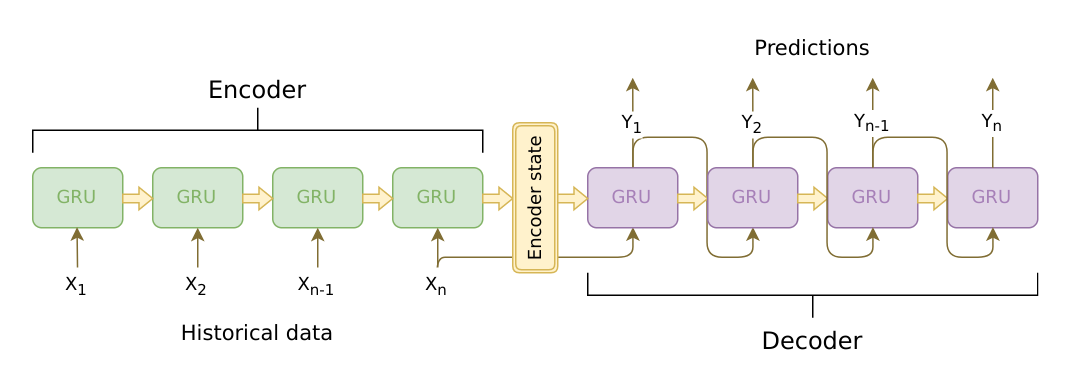
EncoderとしてcuDNN GRUを使った.cuDNN GRUはドキュメントが貧弱だが,通常のTensorFlowのRNNCellsより5倍から10倍ほど高速だ.
DecoderとしてGRUBlockCellをtf.while_loop()でラップして使った.ループの中で,直前の時系列の予測結果を次のセルに入力する.
Working with long timeseries
LSTM/GRUはせいぜい100から300アイテム前の情報しか保持できないため,700日分のpageviewを使用する今回のタスクには,直接利用できない.
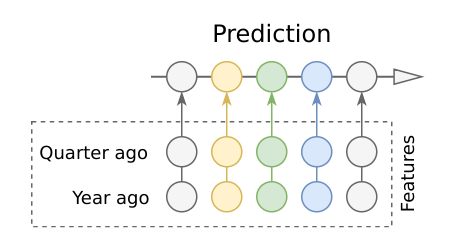
最初はattention的な考え方で,一年前と四半期前のEncoderの出力をDecoderの入力に使うことを考えた.しかし,処理が重い割に性能が出なかった.

結局,一年前と四半期前のpageviewをそのまま特徴量として使うことに決めた.Attentionより良い性能を得た.また,これによりEncoder長をむやみに長くする必要がなくなった.過去60から90日のアイテムを利用する場合でさえ,上記のモデルより高速に優れた予測が可能だった.
Losses and regularization
コンペの評価で用いられるSMAPEは0付近で微分不可能な動きをするため,学習に利用しなかった.代わりに微分可能なSAMPE関数を独自に実装して利用した.
最終的な出力は整数値に丸めた.負の出力値は0に修正した.
Regularizing RNNs by Stabilizing Activationsを参考にRNNの正規化を試みたが,改善効果は微々たるものだった.
Training and validation
学習時は,Training Deep Networks without Learning Rates Through Coin BettingのCOCOB optimizerと,Gradient clippingを合わせて使った.COCOBは自動で学習率を調整してくれるから便利だし,従来のモーメントベースのoptimizerより高速だ.
TrainingとValidationの分け方として,次の二つが考えられる.
- Walk-forward split:厳密にはSplitではない.TrainingとValidationでタイムフレームをずらす方法.
- Side-by-side split:王道のSplit.データセットを独立な集合に分割し,それぞれTrainingとValidationに利用する.
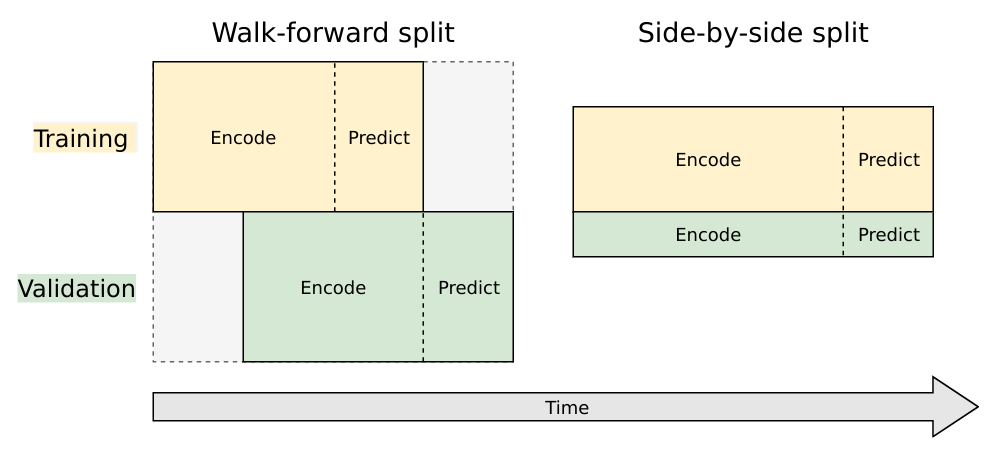
今回は両方共利用した.Walk-forward splitは今回のタスクと親和性が高いが,Validation用に新しい日付のデータセットを残しておく必要があるため,古い日付のデータセットしか学習に使えない.一方でSide-by-sideは新しい日付のデータセットも学習に使えるが,Validationの性能がTrainingデータに大きく依存してしまう.
ハイパーパラメータのチューニングにのみSplitを利用し,全てのデータを使って再度学習したモデルで,最終的な予測を行った.
Reducing model variance
今回の入力データ(Wikipediaのpageview)は非常にノイジーなので,Varianceを下げる工夫が必要だった.
- 過学習直前(と思われる)前後1000エポックで,10個のチェックポイントを作成.
- サンプルを分割し,三つの独立なモデルを作成し,それぞれチェックポイントを作成.
- 合計30のチェックポイントに対して,SGD averaging(ASGD)を適用する.つまり学習結果のパラメータを平均して,予測に使う.
Hyperparameter tuning
SMAC3を使ってチューニングした.SMAC3は:
- 条件付きチューニングが可能.例えば,
n_layer > 1のときのみ,第二層をdropoutするなど. - モデルのVarianceを考慮可能.
感想
大筋は理解できた(気になった).学習時のDecoderの扱いなど,ソースコードを確認した方が良いかもしれない.
参考
- Kaggle,Web Traffic Time Series Forecasting,1st place solution
- Arturus/kaggle-web-traffic - GitHub
- SMAC3 documentation
-
seq2seqのDecoderの学習時って,普通,直前の時系列の予測結果は使わずに,ターゲットデータを使うんじゃなかったっけ?ソースコードを確認した方が良いかもしれない. ↩
Subscribe via RSS